Composing Transferable Skills and Verbal Reflection Improves Agent Performance
Friday, June 19, 2026Building dynamic context to orchestrate actors in large language model systems is an active area of research, essential to producing high-quality results on long-horizon tasks. But combining the different effective methods being pursued is not straightforward. This report asks a narrow, concrete version of that question: do two well-known in-context learning methods — skill libraries and verbal reflection — compose?
We propose rSSO, a composition of skill-library learning (SSO) and verbal reflection (Reflexion). rSSO maintains two distinct memory systems: one with skills distilled from successful trajectories, the other with reflections drawn from failed trajectories. Evaluated in the text environment ScienceWorld, rSSO achieves performance neither method achieves alone — outperforming SSO by 8.95 and Reflexion by 6.28 points.
Two ways agents learn without weight updates
LLM agents in interactive environments learn from experience without weight updates by accumulating in-context memory across attempts. Two prominent families of methods occupy this design space.
Skill libraries (SSO, Voyager, ExpeL) extract reusable action sequences from successful trajectories. Each skill is abstracted into an instruction list and a target state, then retrieved per step at run time via embedding similarity to the current observation.
Verbal reflection (Reflexion, CLIN, Self-Refine) compiles summaries of what went wrong from failed trajectories. These summaries are prepended to the actor’s prompt on subsequent trials.
The two modalities draw from complementary signals — success versus failure — and inject information at complementary points in the prompt — per-step retrieval versus a once-per-trial preamble. That structure is exactly what makes them candidates for composition. If they compose, we get performance gains for free by combining them, and a template for integrating further methods. If they don’t, the two are either redundant or adversarial in some characterizable way. We resolve the question empirically on ScienceWorld using Claude Sonnet 4.6 as the base model.
Contributions:
- Composition of SSO with Reflexion (rSSO). Across four learning algorithms (ReAct, Reflexion alone, SSO alone, and their composition rSSO) under the SSO adaptation setting, rSSO outperforms all others, scoring 8.95 points above SSO and 6.28 above Reflexion.
- Claude Sonnet results on ScienceWorld. To our knowledge no prior published numbers on this benchmark use a Claude model. SSO alone on Sonnet 4.6 reaches 79.46, within 4.24 points of the original GPT-4 number (83.7), which we treat as a faithful-within-tolerance reproduction.
- Evidence characterizing where composition helps. The gains concentrate on task types where SSO alone plateaus mid-run. There, reflection contributes a verbal account of why the plateau persists that per-step skill retrieval does not surface.
Background: ScienceWorld and the SSO adaptation setting
ScienceWorld is a text-based science simulation with 30 task types spanning physics, chemistry, biology, and genetics. Each task has multiple variants using different target substances, locations, or thresholds. The actor navigates rooms, manipulates objects, and registers a result via a focus on action. Scoring is in [−100, 100], with positive partial credit for sub-goals, −100 for committing to a wrong answer, and 100 for correct completion.
SSO evaluates two settings, adaptation and transfer; we follow its adaptation setting on an 18-task subset. For each task, the actor attempts each of 10 held-out test variants with 5 trials per variant. Learning is allowed between trials within a variant, but actor memory is cleared between variants. Under this setting with GPT-4, SSO scores 83.7, ReAct 29.6, and Reflexion 39.4.
Skill Set Optimization (SSO) maintains a per-variant skill library. After each trial, the trajectory is split at positive-reward boundaries into sub-trajectories of 3–6 steps as skill candidates. Cross-trajectory matching identifies recurring action patterns, scored on coverage, reward, state similarity, and action similarity. Beam search selects a non-overlapping skill set, and each skill is verbalized by a 3-stage prompt (summary, instructions, target state). At run time the actor receives the top-3 skills per step by cosine similarity between the skill’s stored initial state and the current state.
Reflexion maintains a per-task FIFO buffer of natural-language reflections (default size 3). After each failed trial (env score < 100), the trajectory is summarized into a single reflection emphasizing what went wrong and what to try differently. On the next trial, all buffered reflections are prepended as a Plans from past attempts block. No reflections are generated on success.
Why these have not been composed. The SSO paper compares against Reflexion as a baseline and reports SSO outperforming it by a wide margin on adaptation (83.7 vs. 39.4), positioning Reflexion as a weaker alternative. But the two methods’ memory layouts — per-step skill retrieval into the action-template region, and a once-per-trial reflection prepended to the system message — occupy non-overlapping prompt regions, which suggests they are composable. To our knowledge no published study has tested them together.
Method: two memories, two triggers, two prompt regions
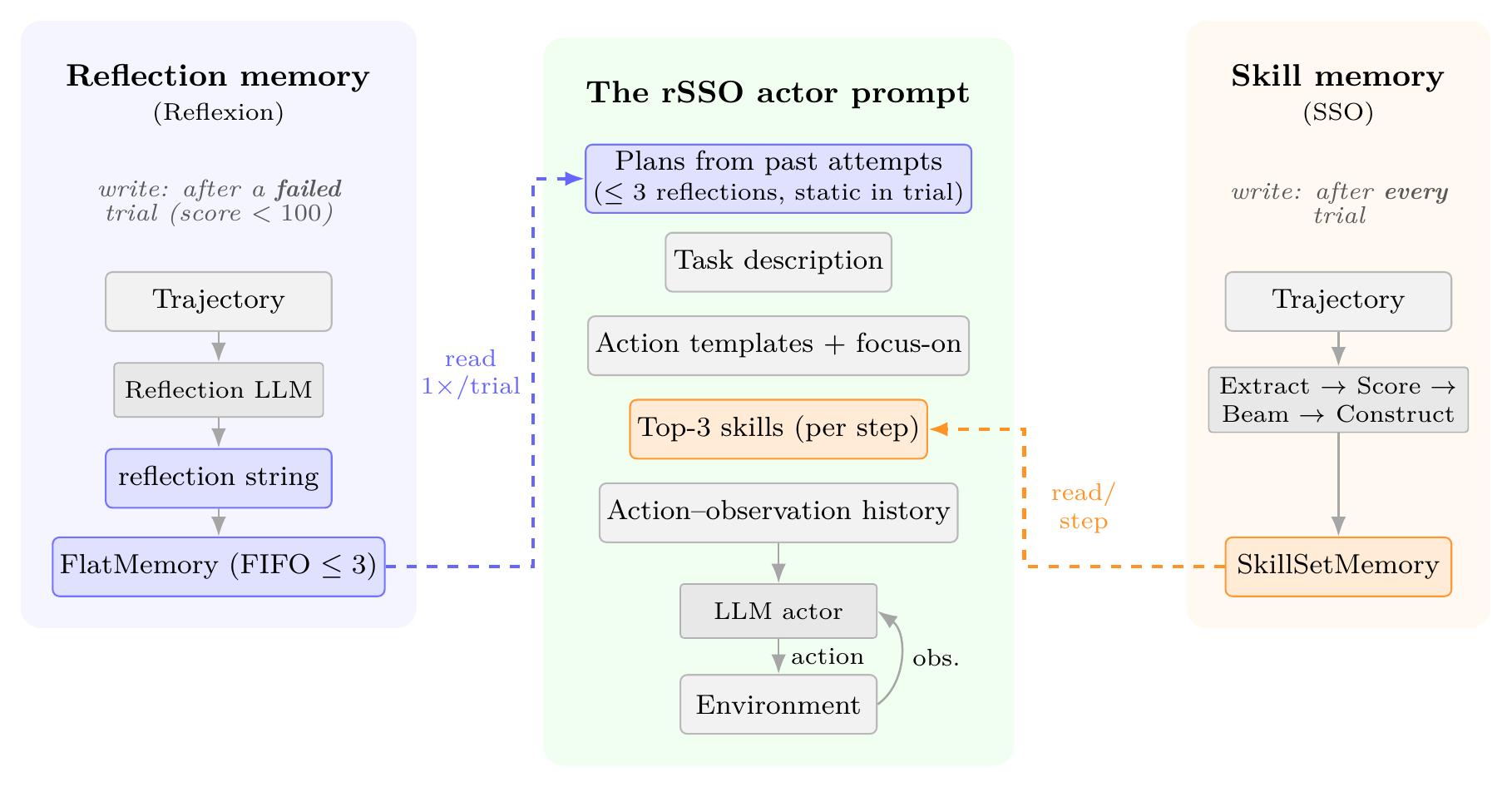
rSSO composes two distinct memory aggregation methods. Center: the actor prompt at run time; the reflection preamble (blue) and the per-step skill region (orange) occupy non-overlapping positions, and all gray regions are inherited unchanged from pure SSO. Left: Reflexion’s reflection memory is written by a single LLM call after a failed trial and read once as the preamble (static through the trial). Right: SSO’s skill memory is written after every trial by the cross-trajectory pipeline and read per step into the skill region. The two stores draw on disjoint signals — successes for skills, failures for reflections — and never read or write the same prompt region.
rSSO composes SSO and Reflexion by maintaining two distinct memories that survive across the within-variant trials. They are written by separate LLM calls, on separate triggers, and read into non-overlapping regions of the actor prompt:
- A SkillSetMemory (SSO’s data structure) holding trajectories, candidate skill windows, and the current beam-searched skill set. Updated after every trial via sub-trajectory extraction, cross-trajectory matching, scoring, beam search, and 3-stage LLM skill construction.
- A FlatMemory (Reflexion’s data structure) — a FIFO queue of up to N=3 verbal reflections. Updated after every failed trial (env score < 100) by appending a single LLM-generated reflection.
At each step the actor prompt is assembled top to bottom:
Plans from past attempts <- reflections (<=3), loaded once at trial start
Task description
Action templates + focus-on warning
Top-3 skills <- retrieved fresh every step, by similarity to current state
Action-observation history
The reflection preamble is read once per trial; the skills are retrieved fresh on every step, matching SSO’s per-step-retrieval behavior. rSSO adds no new components: it keeps SSO’s 3-stage skill verbalization (after every trial) and adds one reflection call per failed trial. The actor’s structured-output contract — its reasoning, current subgoal, and action — is unchanged from SSO. The two memory stores draw on disjoint signals (successes for skills, failures for reflections) and never read or write the same prompt region.
Experimental setup
We follow the SSO adaptation setting: 18 task types, 10 test-split variants per task, 5 trials per variant, memory cleared between variants. Max steps per trial is 1.5× the gold-action-sequence length, dynamic per variant. Of the 18×10 = 180 nominal variants, 164 are available in the test split.
ScienceWorld returns a positive-reward accumulator score in [0, 100] and an environment score in [−100, 100] that reaches 100 only on a correct solution. We report three metrics, following SSO:
- Mean — from the accumulator score, taken per variant as the best across 5 trials, averaged over 164 variants.
- Solve — fraction of variants reaching environment score ≥ 100 on any trial.
- Acc100 — fraction reaching accumulator score ≥ 100 on the best trial.
Both actor and reflection/skill-construction use Claude Sonnet 4.6. We use all-MiniLM-L6-v2 for skill-retrieval similarity (a deviation from SSO’s text-embedding-ada-002, discussed under Limitations). We verified our SSO implementation against the reference implementation, matching its 3-stage skill generation, cross-trajectory matching, beam search, and LLM-based deduplication.
Prompt scaffold inheritance. Each method uses the prompt scaffold published with it: SSO and rSSO use the SSO action-template prompt; ReAct and Reflexion use the ReAct-style prompt. This matches the comparison the SSO paper itself uses. A consequence is that trial 1 of each method (empty memory) is not identical across rows: with empty memories, SSO reaches 75.30 in trial 1 while Reflexion reaches 58.37. We read this gap as evidence that SSO’s contribution includes the prompt-scaffold design as a static prior, in addition to the skill-retrieval mechanism. The composition gain we report (rSSO − SSO, +8.95) is unaffected, since both rows share the SSO scaffold and differ only in the presence of reflection memory.
Results
rSSO reaches a mean of 88.41, the best of the four methods on all reported metrics, exceeding SSO by 8.95 points (79.46 → 88.41) and Reflexion by 6.28 (82.13 → 88.41). Across task types, rSSO matches or exceeds SSO on 16 of the 18 task types, significant at p ≈ 0.009 (two-sided Wilcoxon signed-rank).
| Method | Scaffold† | Mean | Solve | Acc100 |
|---|---|---|---|---|
| ReAct | flat | 58.37 | 62/164 | 56/164 |
| Reflexion | flat | 82.13 | 114/164 | 102/164 |
| SSO | SSO | 79.46 | 113/164 | 96/164 |
| rSSO | SSO | 88.41 | 134/164 | 112/164 |
| ReAct (GPT-4) | flat | 29.6 | — | — |
| Reflexion (GPT-4) | flat | 39.4 | — | — |
| SSO (GPT-4) | SSO | 83.7 | — | — |
ScienceWorld best-of-5 results on the SSO adaptation setting (N=164 test variants). Top panel uses Sonnet 4.6; rSSO exceeds SSO alone by +8.95 using the same scaffold and code. Best in bold, second-best underlined. Bottom panel shows existing GPT-4 results. †Each method inherits the prompt scaffold published with it; within-scaffold deltas isolate the memory configuration, while cross-scaffold deltas have confounders.
The outperformance is monotone across trials. The per-trial cumulative best-of-t means show rSSO ahead of SSO alone at every t ≥ 2: 84.49 vs. 76.63 at t=2, 85.80 vs. 77.57 at t=3, 87.55 vs. 78.09 at t=4, and 88.41 vs. 79.46 at t=5. The gap opens at t=2, when reflection memory first carries information, and stays open. rSSO has a large trial 1→2 jump of +9.42; SSO alone makes small per-trial gains.
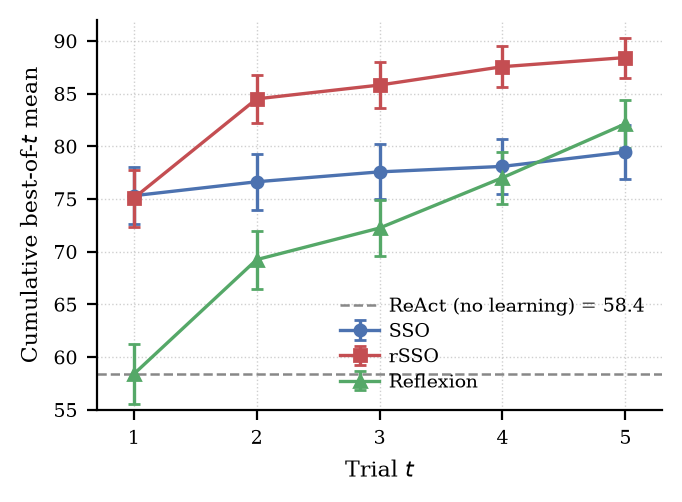
Per-trial cumulative best-of-t mean across 164 task variants (Sonnet 4.6). Error bars are SEM across variants. rSSO (red) leads at every t ≥ 2. Reflexion-alone (green) crosses SSO-alone (blue) at t=4 and finishes +2.67 above it at t=5; the ReAct baseline (58.37, dashed) is reported as t=1 of the Reflexion run.
Where the gain concentrates. The increase over SSO is not uniform. Tasks where SSO alone plateaus at a sub-100 score on every trial — where skill retrieval finds a partial procedure but the actor never closes the last step — are the ones reflection rescues most often. Reflection adds a verbalized account of the last failure that gives the actor a missing piece of context the per-step skill prompt does not surface. Tasks SSO already solves at t=1 (≈60% of variants) cannot gain from reflection, because no failure transcript is ever produced.
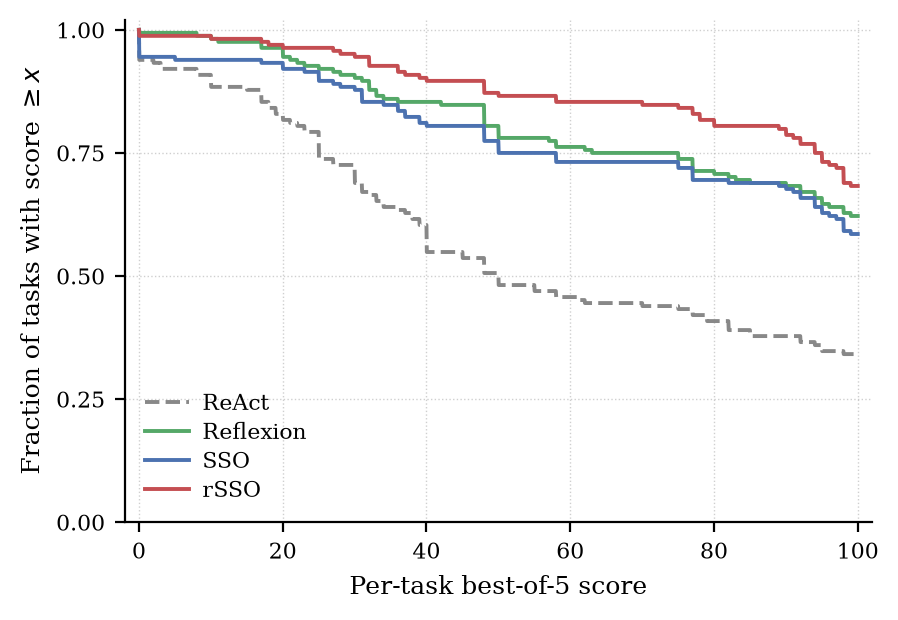
Survival function of per-task best-of-5 scores across the four Sonnet 4.6 conditions: S(x) = P(score ≥ x). rSSO (red) dominates all other methods at every score. Reflexion (green) and SSO (blue) intertwine through the middle, with Reflexion edging out SSO from x ≈ 70 upward. ReAct (dashed) sits well below all three.
Reflection’s gain transfers across scaffolds. The trial 1→2 improvement is large in both scaffold contexts: +10.87 for Reflexion-alone, +9.42 for rSSO. The two scaffolds reach very different absolute levels at t=1, but the marginal effect of adding verbal reflection is comparable — consistent with skill libraries and verbal reflection drawing from non-overlapping signals at different prompt positions.
In the flat scaffold, adding reflection raises the score from 58.37 to 82.13, an increase of 23.76 points — substantially larger than the within-SSO-scaffold composition increase of 8.95. We caution against over-reading this cross-scaffold comparison: scaffold and memory both differ between those rows, and the within-scaffold increases are the controlled comparisons. Still, the pattern is consistent with a stronger base model making more of the verbal-reflection channel and less of SSO’s static prompt-scaffold prior. (The original GPT-4 Reflexion result on this setting is 39.4, suggesting the GPT-4 → Sonnet 4.6 jump is over 42 points on Reflexion alone — enough to largely close the reported 44.3-point Reflexion-vs-SSO gap.)
A concrete example: recovery on a plateau task
To illustrate how reflection supplies context that per-step skill retrieval does not, consider boil::22, a variant on which SSO alone plateaus and rSSO recovers; its best-of-t scores across the five trials are 0, 0, 0, 75, 100. The early failures stem from a recurring error: confusing a tin container (a tin cup) with elemental tin as a substance, and searching the kitchen. By trials 4 and 5 the actor’s reasoning explicitly cites the accumulated reflections and corrects course:
Trial 4. “Past attempts warn against confusing tin containers with tin substance, and suggest searching chemistry labs or workshops.”
Trial 5. “Past attempts warn to find tin as a pure substance (not a tin cup), likely in a workshop or chemistry lab, and to use a high-temperature source like a blast furnace.”
While the task is still failing, SSO has no successful boil sub-trajectory to retrieve, so this corrective context reaches the actor only through the reflection channel.
Per-task-type breakdown
Per-task-type mean best-of-5 score on the SSO adaptation setting (Sonnet 4.6). Δ_SSO = rSSO − SSO (within-SSO-scaffold composition gain); Δ_flat = Reflexion − ReAct (within-flat-scaffold gain).
| Task type | N | ReAct | Reflexion | SSO | rSSO | Δ_SSO | Δ_flat |
|---|---|---|---|---|---|---|---|
| boil | 9 | 41.3 | 77.8 | 64.6 | 89.8 | +25.2 | +36.4 |
| chemistry-mix | 8 | 71.2 | 81.6 | 82.0 | 82.0 | 0.0 | +10.4 |
| chemistry-mix-paint-secondary-color | 9 | 30.0 | 67.8 | 71.1 | 86.7 | +15.6 | +37.8 |
| find-living-thing | 10 | 52.5 | 88.3 | 52.5 | 90.0 | +37.5 | +35.8 |
| find-plant | 10 | 100.0 | 100.0 | 91.7 | 91.7 | 0.0 | 0.0 |
| freeze | 9 | 45.8 | 59.6 | 48.9 | 63.2 | +14.3 | +13.8 |
| grow-fruit | 10 | 20.8 | 34.7 | 63.9 | 77.0 | +13.1 | +13.9 |
| grow-plant | 10 | 45.7 | 71.1 | 77.9 | 78.2 | +0.3 | +25.4 |
| identify-life-stages-1 | 5 | 61.6 | 100.0 | 95.4 | 82.0 | −13.4 | +38.4 |
| identify-life-stages-2 | 4 | 46.5 | 46.5 | 68.5 | 71.5 | +3.0 | 0.0 |
| inclined-plane-determine-angle | 10 | 44.0 | 99.0 | 99.0 | 93.0 | −6.0 | +55.0 |
| inclined-plane-friction-named-surfaces | 10 | 87.0 | 100.0 | 100.0 | 100.0 | 0.0 | +13.0 |
| lifespan-longest-lived | 10 | 62.5 | 95.0 | 87.5 | 100.0 | +12.5 | +32.5 |
| lifespan-shortest-lived | 10 | 60.0 | 95.0 | 77.5 | 95.0 | +17.5 | +35.0 |
| measure-melting-point-known-substance | 10 | 61.7 | 98.5 | 80.3 | 98.5 | +18.2 | +36.8 |
| mendelian-genetics-known-plant | 10 | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 |
| mendelian-genetics-unknown-plant | 10 | 24.5 | 50.7 | 68.7 | 76.6 | +7.9 | +26.2 |
| use-thermometer | 10 | 86.8 | 96.1 | 97.3 | 99.1 | +1.8 | +9.3 |
| Overall | 164 | 58.37 | 82.13 | 79.46 | 88.41 | +8.95 | +23.76 |
Across the 18 task types, Δ_SSO is non-negative on 16 and strictly positive on 12 (four tie exactly). A Wilcoxon signed-rank test over the 18 deltas gives W=12, p ≈ 0.009 (two-sided); an exact sign test on the 14 non-tied types (12 favoring rSSO) gives p ≈ 0.013. The two exceptions — identify-life-stages-1 (−13.4) and inclined-plane-determine-angle (−6.0) — both show large positive within-flat-scaffold gains (+38.4 and +55.0), so reflection does help under the ReAct scaffold; the SSO scaffold simply already extracts most of the available signal on those tasks.
Limitations
This study focuses on composition and does not vary the base model: all numbers use Claude Sonnet 4.6, and the cross-model GPT-4 row is landscape context, not a controlled comparison. We report only ScienceWorld; whether rSSO transfers to other interactive-agent benchmarks (ALFWorld, WebShop, TAU-Bench) is open. Because the two memory aggregation methods do not interfere, we expect the composition to transfer, but leave that to future work.
The empty-memory trial-1 gap between SSO and Reflexion (75.30 vs. 58.37) bounds the prompt-scaffold contribution from above but does not separate it from the skill-retrieval contribution; the full decomposition (ReAct and Reflexion under the SSO scaffold with empty skill libraries) remains open. Finally, our reproduction makes three choices that favor comparability over matching the published SSO/GPT-4 numbers — MiniLM-L6-v2 embeddings, no learned skill-scoring feedback loop, and Reflexion’s default buffer of 3 — each held fixed on both sides of the comparison it could affect, so they can shift absolute scores but not the relative differences reported.
Conclusion
We asked whether two in-context learning methods — skill libraries and verbal reflection — compose, and in ScienceWorld they do. Their composition, rSSO, outperforms both constituents (by 8.95 over SSO and 6.28 over Reflexion), reaching a level neither attains alone, and without any new components: just two memories, one of skills distilled from successes and one of reflections drawn from failures. The gain concentrates on the task types where SSO plateaus, where a verbal account of the last failure supplies context that per-step skill retrieval does not surface. This points to a broader hypothesis for future work: distinct memory aggregation methods drawing on complementary signals can be composed to improve agent performance.
PDF version of the above.