Multi-agent Reinforcement Learning
Abstract: We address the problem of how autonomous agents that sense and act in their environment can learn to choose optimal actions to achieve their goals. We will use the Q-learning algorithm, which learns optimal control strategies from delayed rewards, even when agents have no prior knowledge of the effects of their actions on the environment. We will experiment with two different strategies for choosing actions, an ε-greedy strategy that randomly chooses actions and an ε-greedy strategy that chooses actions weighted by their estimated value.
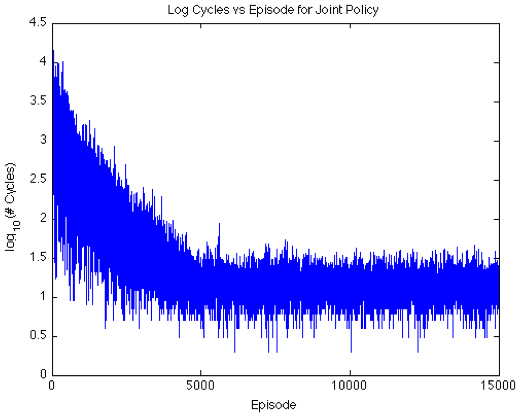
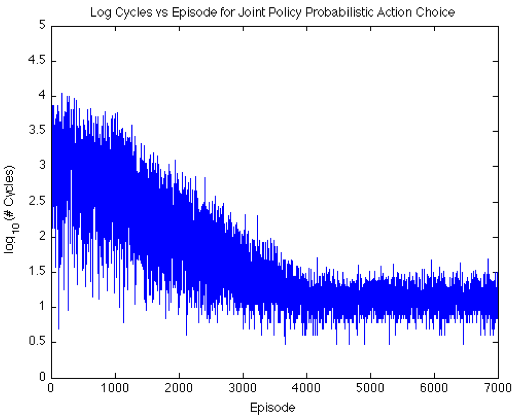
The above graph, random choice, converges slower than the below graph, probabilistic choice, which uses a Boltzmann-like annealing. All project code was written in Python. Download the multi-agent learning project report.
This was a joint project with Davide Modolo.