Thursday, August 18, 2022
Half of the world’s population is unable to obtain essential health services or the typical healthcare services offered in large facilities. The rise of community health workers and community health service programs have been transformative, but they are at the limits of their ability to improve outcomes. In our work in underdeveloped nations around the world, we have heard community health workers report being overburdened and saddled with increasing responsibilities.
Recent developments show a realization that providing health services to 4 billion underserved people will require transitioning to digital tools, including smartphones, for data collection and service delivery tracking. As the smartphone’s availability and capability has increased, it has become a critical tool for delivering healthcare, especially to those at the limits of existing health system service networks. Both healthcare practitioners visiting homes and based in facilities use healthcare apps to register, monitor, and deliver services to patients. These apps and the smartphones they run on function as off-line capable EMRs with use-case specific features for the particular health services they are delivering.
Most of the smartphone apps used in global healthcare store information in ad-hoc proprietary formats, and implement healthcare workflows that are not codified at the software level. This lack of standards limits and significantly increases the cost and technical sophistication needed to share resources — be they data, software, or processes and procedures — between independent or collaborating projects using healthcare apps, which hurts the long term viability of digital health tools. (Programs like Digital Square’s Global Goods were created to solve this exact problem). In addition, part of what holds organizations back from deploying apps based on standards like FHIR is the lack of mature tooling to run FHIR on smartphones. We worked with WHO and Google to create a set of innovations to solve these obstacles.
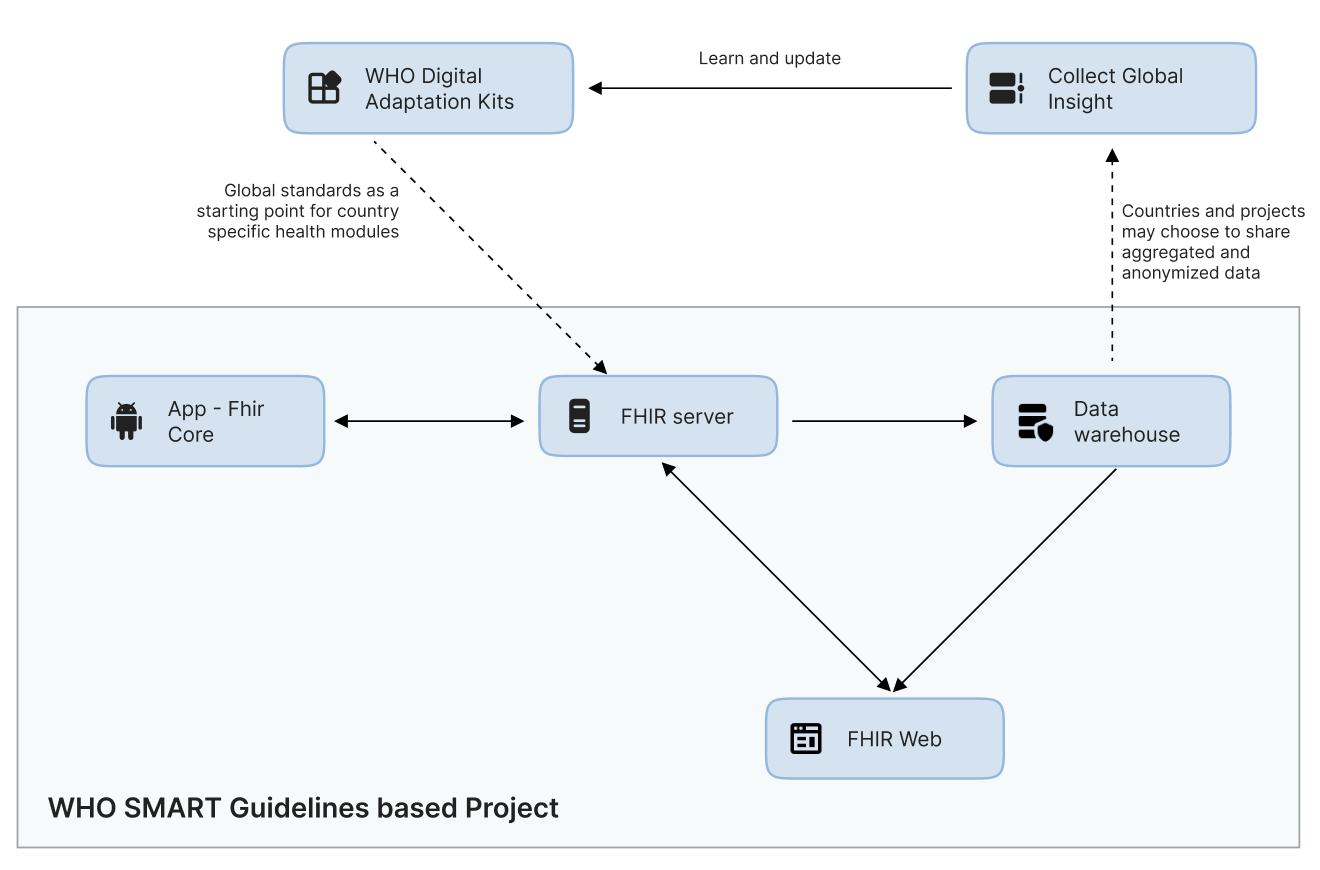
The WHO Smart Guidelines are a framework for computable healthcare guidelines that use FHIR to define the recommended algorithms for health protocols, such as antenatal care. To bring these guidelines to healthcare projects we have been collaborating with Google on the foundational layer needed for FHIR compatible healthcare apps, called the Android FHIR SDK, which implements the FHIR API on Android smartphones.
Called OpenSRP FHIR Core, the innovation leverages the WHO SMART Guidelines, in combination with the Android FHIR SDK, to create the first configurable platform on Android that keeps all data, as well as all meaningful rendering and business logic, in the FHIR format and uses this for storage, queries, and execution.
In Liberia, where FHIR Core is being piloted, 11,000 children under 5 die every year. Globally the WHO estimates that there are 5 million children under 5 who died of preventable and treatable causes. The pilot targets reproductive, maternal, newborn, and child health, and aims to eliminate avoidable child deaths through better tracking or health information and timely targeting of treatments.
Our hope and goal is to reduce the number of Liberian children under 5 deaths, and through this learn lessons to apply to our work with partners in other countries and international health organizations to reduce the number of global children under 5 deaths. Ultimately, reaching the underserved populations will require many pieces to fit together. With FHIR and the WHO SMART Guidelines, our goal is to make it easier to coordinate a cooperative and unified effort.
Wednesday, March 16, 2022
What would the world look like if everyone had access to Rapid Diagnostic Tests for Covid-19, Malaria, and other communicable diseases, that could be read and easily understood on a smartphone, and that were used as soon as the first person in your community showed symptoms?
Last Thursday and Friday, the Ona Team had the honor of hosting an exceptionally productive Symposium on Open Guidelines for RDTs to discuss this and other questions. We were happy to see the enthusiastic participation and insightful questions coming from everyone who joined us. Below is the welcome slide deck, to give you a sense of the content.
We would like to thank all of our panelists, Rigveda Kadam from FIND, Luciana Rajula from PATH, Marc Abbyad from Medic, Dr. Gerhard Nebe-Von-Caron from Mologic, and Shiven Bhatt from Becton Dickinson. You can find a description of those panels on the event page. Mo Abdo from Zebra also gave an engaging walkthrough of environmental sensors embedded in QR codes – thank you Mo! Mo’s presentation stressed how Covid-19 has made clear it is essential to know the quality of the diagnostic you are using, whether conducted by a healthcare worker or as a self-test. During the Symposium, our partners at the Indonesia based Summit Institute of Development (SID) teamed up with members of the Ona team to present the results of the OG RDT Malaria and Covid-19 field studies in Kenya and Indonesia. Thank you to Yuni Dwi Setiyawati (SID) and Bella Okiddy (Ona) for illustrating how the novel advantages of OG RDT deployments are linked to improved impact.
We would like to acknowledge and thank the Bill and Melinda Gates Foundation for supporting us in this project and the essential inputs of the officers we worked with on it, including Arunan Skandarajah, Annie Ye, and Teresa Ruiz Herrero. Nearly all of the presentations are now linked from the event page, and we will be adding those remaining as they are ready.
Friday, February 25, 2022
HL7 FHIR provides a standardized and popular way for digital health systems to represent health data and associated processes. We are excited to introduce Quest, an open source app that lets you use FHIR to define forms and capture data to take advantage of the growing Android FHIR and WHO SMART guidelines ecosystem.
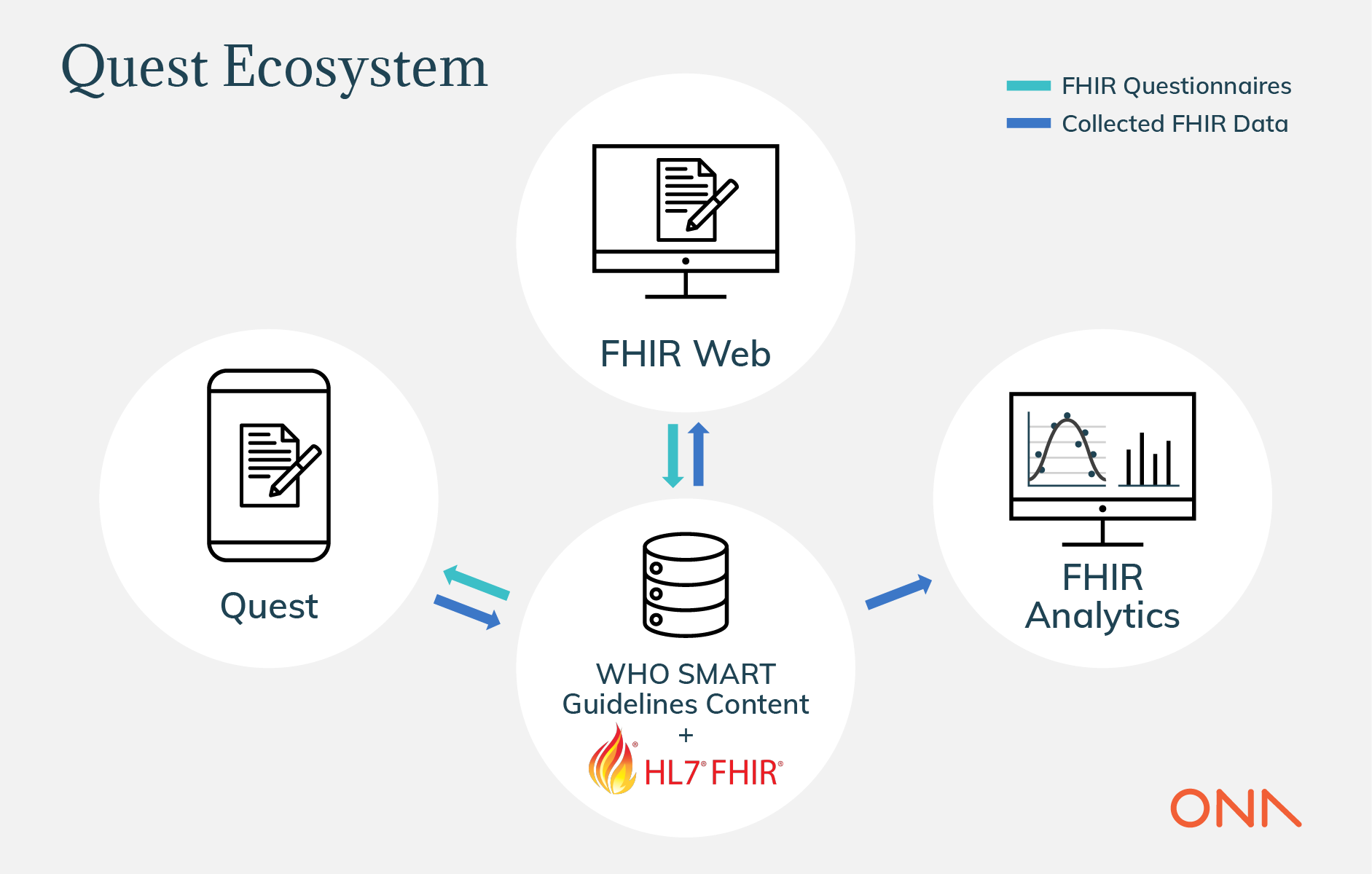
As digital health platforms embrace FHIR, the barriers to interoperability will decrease, making it possible to interact with patient data across different health systems to inform clinical decisions and coordinate care. Adoption of FHIR also enables semantic interoperability, i.e. the ability to exchange and understand data with unambiguous, shared meaning across systems. This standardization and aggregation of data is needed for health systems to generate and operationalize ML/AI driven insights.
Key to FHIR’s ability to collect standardized data is the use of digital forms, rendered using the FHIR Questionnaire resource. Questionnaires support complex clinical logic and the ability to map data elements to medical terminology codes like ICD11. We can map the data captured in FHIR Questionnaires directly to other FHIR resources (such as Patients, Observations, etc) making them ideal for creating FHIR native health applications.
While the FHIR implementation guide for Structured Data Capture (SDC) is a well defined specification, digital tools that accessibly capture FHIR data natively are still largely non-existent. To address this we created Quest (short for Questionnaire), a digital health app-runner built upon the Android FHIR SDK. Quest makes it possible for non-technical users to develop and implement FHIR native data collection and case management apps.
Using Quest a person with no programming experience can design and deploy a simple data collection or case management app using FHIR Questionnaires they have authored. In developing Quest, we have initially focused on (1) enabling FHIR native on and off-line data collection on mobile devices, and (2) adding support for equivalent data capture capabilities via web forms. To promote data security, Quest will support the administration of data collection via authenticated users and secure, encrypted stores on FHIR compatible clouds and servers, such as Google’s Cloud Healthcare API and HAPI FHIR. These data stores support programmatic export and API based access to collected FHIR data, simplifying integration with external analysis and monitoring platforms.
We are excited for these tools to lower the barrier to adopting FHIR native apps. We have been aggressively working with a great team of technical and implementing partners who are bringing the benefits of FHIR to healthcare and other projects around the globe. We welcome you to join Ona and our partners in contributing and discussing the implementation strategy on the FHIR Core code repository, including iterating on early drafts of the Quest documentation.
Sunday, March 15, 2020
Here we analyze the COVID-19 case data to create simple charts and time series models. This is meant as a review of time series analysis methods and not to accurately predict the future course of the pandemic. These models are based on the daily case data only, they are all univariate, and they do not consider environmental changes (e.g. travel restrictions, quarantines, and event cancellations).
The rest of this post describes the functionality of the COVID-19 Time Series Analysis IPython Notebook and includes charts with the data available as of March 15th, 2020. Feel free to use, modify, extend, and contribute to the notebook.
Fetch COVID historical case date
Each time we run the build_data function we will:
This fetches all data available in the CSSEGIS COVID-19 repository at the time it is run.
Use the unify_names function to combine multiple countries and/or provinces/states into a single country. This resolves problems when the names of single countries are inconsistent in the CSSEGIS datasets.
Use the plot function to produce total cases and case per day charts for a set of countries and metrics, passed as parameters.
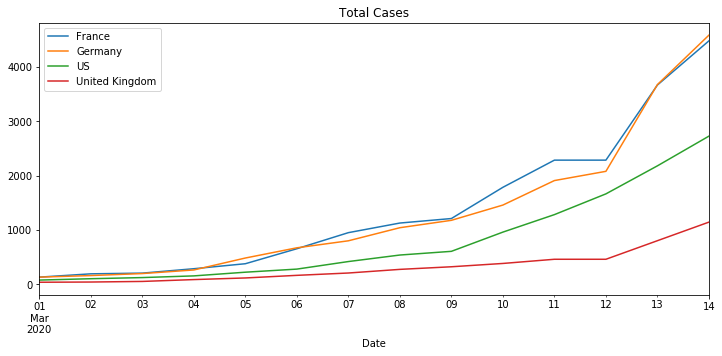
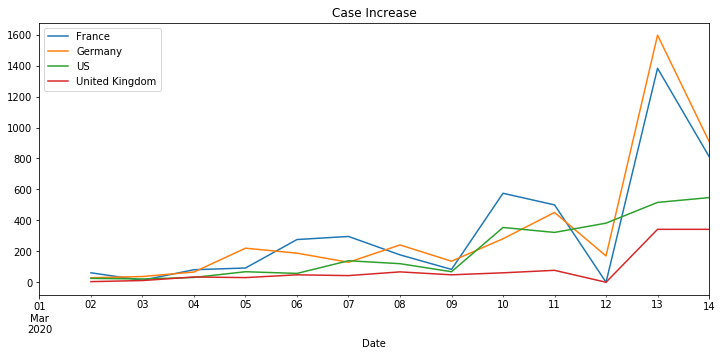
Naive Time Series Models
This section requires that the grouped_df DataFrame and the all_countries list exist. These models are not run in parallel, but they can be. These models are incredibly naive, we are only considering the previous case numbers, nothing exogenous.
Use the prepare_data function to limit the countries and metrics. Currently this can model univariate data, i.e. it only considers a single country (or province/state) at a time. It would be interesting to use VAR or other multivariate models to capture the interdependence between countries.
We have written forecasting functions that use the ARIMA and Holt Winters Exponential Smoothing time series analysis methods. Additional forecasting methods in the same format as these functions should work fine.
The grid_search function takes a map from forecasting functions to a list of configurations per forecasting function and evaluates all configurations using a walk forward method with a 2/3rds training and testing split. There is no validation or cross-validation step. This function returns a list of forecast function, configuration, and mean squared error (MSE) tuples ordered by increasing (i.e. worse) MSE.
On March 15th, 2020, when evaluating the US case count, an ARIMA model with order (2, 1, 4) had the lowest MSE of 4,933. The below chart plots the actual and predicted values for the testing data.
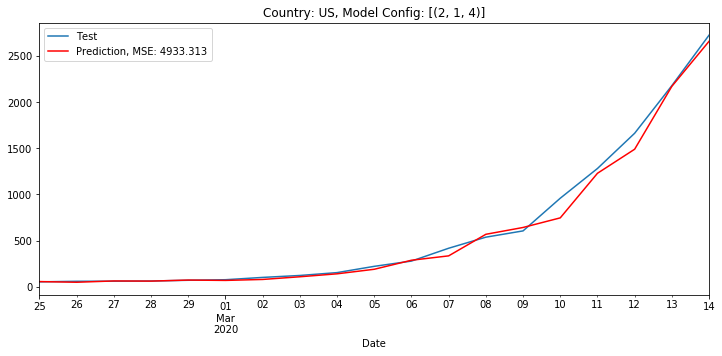
Below is the result if we have this best fit model (best as in lowest MSE) predict the number of cases for the next two weeks. The gap is because we do not connect the last day of actual data to the first day of predicted data. We show predicted cases as a red dotted line.
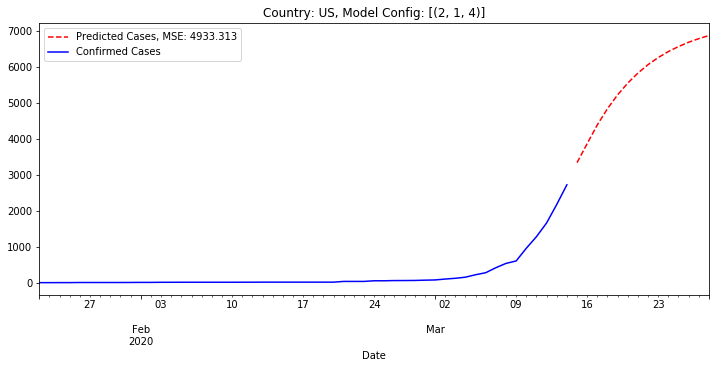
Looking at a wider set of models, below is the result for the next week showing all models with a MSE below 20,000 in pink and the best model in dark red. We see that when considering all our models there are a variety of possible outcomes.

There are many other factors and methods that would improve these models. This is meant as a review of time series analysis methods and not to accurately predict the future course of the pandemic. Please take a look at the COVID-19 Time Series Analysis IPython Notebook to explore and extend the code.
Monday, July 30, 2018
I was recently interviewed by Tobias Macey for the Data Engineering Podcast, the podcast about modern data management. We talked about the history of Ona and some of the technical challenges we’ve had to address to build global data collection platforms in humanitarian, international development, and global health verticals. You can check it out here.
With the attention being paid to the systems that power large volumes of high velocity data it is easy to forget about the value of data collection at human scales. Ona is a company that is building technologies to support mobile data collection, analysis of the aggregated information, and user-friendly presentations. In this episode CTO Peter Lubell-Doughtie describes the architecture of the platform, the types of environments and use cases where it is being employed, and the value of small data.